Canton 可观测性配置
在 Canton 节点上配置日志、追踪、指标与健康监控。
在 Canton 节点上配置日志记录、跟踪、指标和运行状况监控。
简介
可观察性(也称为“监控”)可让您确定 Daml Enterprise 解决方案是否正常。如果状态不健康,可观察性有助于诊断根本原因。可观察性由三个部分组成:指标、日志和跟踪。本节对此进行了描述。
为避免因指标和日志消息的数量而不知所措,请按照以下步骤操作:
- 阅读下面的“Daml Enterprise 实践 - 可观察性示例”部分中介绍的了解重要内容的快捷方式,作为构建指标监控时的起点和灵感。
- 有关大多数指标如何公开的概述,请阅读下面的黄金信号和关键指标快速入门部分。它描述了度量命名和标签背后的哲学。
其余部分提供了更详细信息的参考。
Daml Enterprise 实践 - 可观测性示例
Daml Enterprise - Observability Example GitHub 存储库提供了完整的参考示例,用于探索 Daml Enterprise 公开的指标。您可以使用它来探索指标的收集、聚合、过滤和可视化。它是独立的,具有以下组件:
- 一个示例 Docker 组合文件,用于为所有组件创建运行时
- 一些 shell 脚本,用于生成对 Daml Enterprise 解决方案的请求
- 用于抓取指标数据的 Prometheus 配置文件
- Grafana 模板文件,用于以有意义的方式可视化指标,如下面的示例仪表板所示
<图>
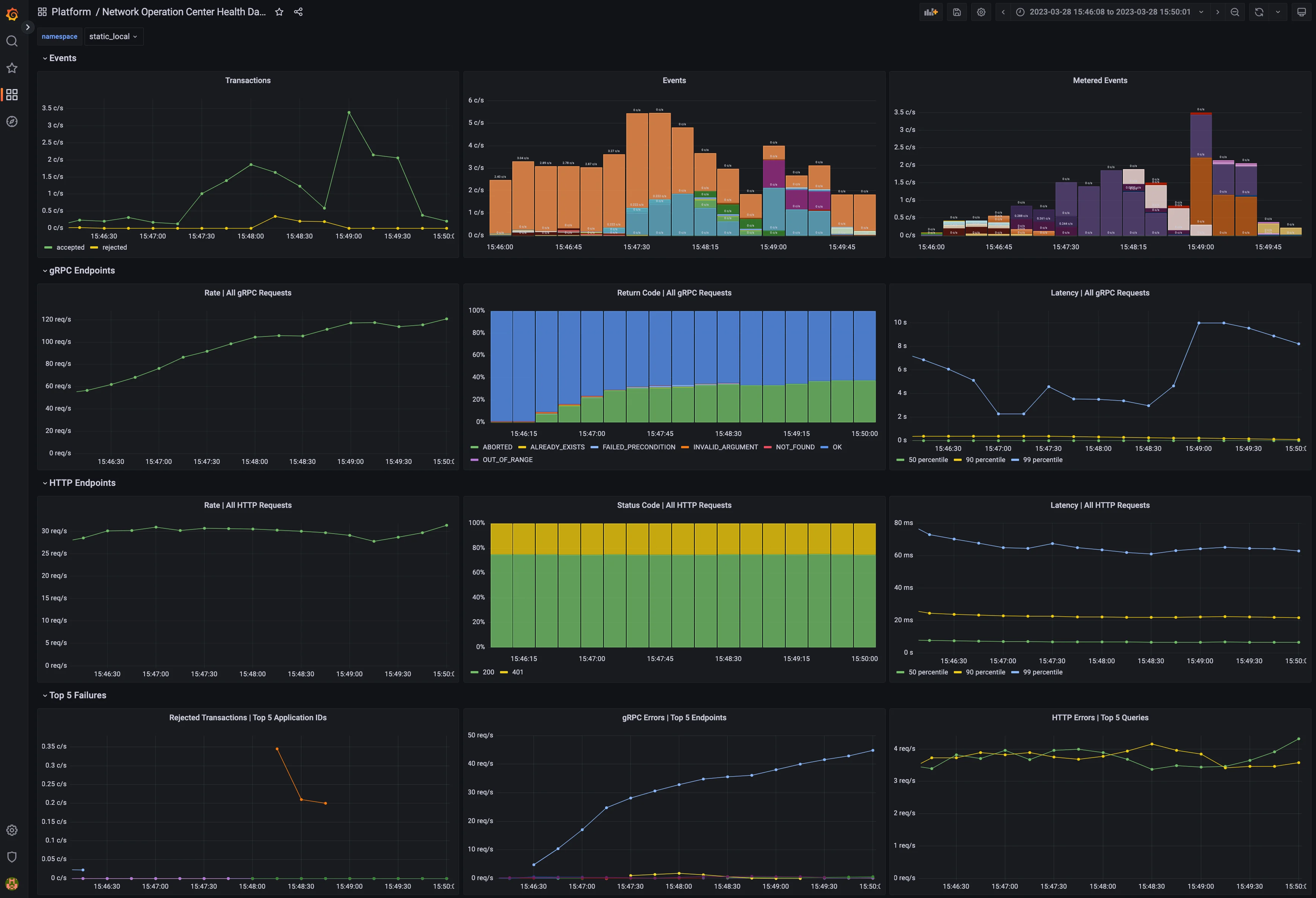
黄金信号和关键指标快速入门
监控微服务应用程序的最佳实践是一种称为黄金信号或红色方法的方法。在这种方法中,指标监控确定应用程序是否健康,如果不健康,则确定哪个服务是问题的根本原因。所有端点都支持 HTTP 和 gRPC 端点的黄金信号。还提供了特定于 Daml Enterprises 的关键指标。这些将在下面描述。
每个 HTTP 和 gRPC API 均提供以下黄金信号指标:
- 输入请求率,作为计数器
- 错误率,作为计数器(下面讨论)
- 延迟(处理请求的时间),以直方图形式表示
- 有效负载的大小,作为计数器,遵循 Apache HTTP 先例
您可以使用其随附的标签来过滤或聚合每个指标。添加到每个 HTTP API 指标的检测标签如下:
http_verb:HTTP 动词(例如:GET、POST)http_status:状态码(例如:200、401、403、504)host:主机标识符daml_version:Daml 版本号service:一个字符串,用于标识此进程中正在运行的 Daml 服务或 Canton 组件(例如:参与方、sequencer、json_api)path:向端点发出的请求(例如:/v2/commands/submit-and-wait、/v2/state/active-contracts)
gRPC 协议位于 HTTP/2 之上,因此包含上一节中的某些标签(例如 daml_version 和 service)。默认添加到每个 gRPC API 指标的标签如下:
canton_version: 坎顿协议 版本grpc_code:gRPC 的人类可读状态代码(例如:OK、CANCELLED、DEADLINE_EXCEEDED)- 客户端/服务器 gRPC request 的类型,位于标签
grpc_client_type和grpc_server_type下 - protobuf 包和服务名称,位于标签
grpc_service_name和grpc_method_name下
监控以下其他关键指标:* 二进制仪表指示节点是否健康。这也可用于推断在高可用配置中哪个节点是被动节点,因为它将显示为不健康,而主动节点始终健康。
- 二进制仪表发出节点是主动还是被动的信号,用于识别哪个节点是主动节点。
- 二进制仪表可检测修剪何时发生。
- 每个参与节点都会测量正在进行的(脏)请求的数量,以便用户可以查看是否接近达到
maxDirtyRequests限制。指标为:canton_dirty_requests和canton_max_dirty_requests。 - 每个参与者节点记录参与者接收到的事件(更新)的分布,并允许按事件类型(包上传、聚会创建或交易)、状态(成功或失败)、参与者 ID 和应用程序 ID(如果可用)进行深入分析。计数器称为
daml_indexer_events_total。 - 账本事件请求总计在一个名为
daml_indexer_metered_events_total的计数器中。 - 收集 JVM 垃圾收集指标。
此列表并不详尽。它突出显示了最重要的指标。
设置指标抓取
启用 Prometheus Reporter
建议使用 Prometheus 进行指标报告。支持其他报告器(jmx、graphite 和 csv),但已弃用。任何此类报告器都应迁移到 Prometheus。
可以使用以下方式启用 Prometheus:
canton.monitoring.metrics.reporters = [{
type = prometheus
address = "localhost" // default
port = 9000 // default
}]仅 Prometheus 指标
有些指标仅在使用 Prometheus 报告器时才可用。这些指标包括常见的 gRPC 和 HTTP 指标(可帮助您测量四个黄金 信号),以及 JVM GC 和内存使用指标(如果启用)。下面详细记录了这些指标。
任何标有 * 的指标仅在使用 Prometheus 报告器时可用。
已弃用的记者
可以使用以下方式启用基于 JMX 的报告(仅用于测试目的):
canton.monitoring.metrics.reporters = [{ type = jmx }]此外,指标可以写入文件:
canton.monitoring.metrics.reporters = [{
type = jmx
}, {
type = csv
directory = "metrics"
interval = 5s // default
filters = [{
contains = "canton"
}]
}]或通过 Graphite(向 Grafana)报告,使用:
canton.monitoring.metrics.reporters = [{
type = graphite
address = "localhost" // default
port = 2003
prefix.type = hostname // default
interval = 30s // default
filters = [{
contains = "canton"
}]
}]当使用graphite或csv报告器时,Canton会定期评估与给定过滤器匹配的所有指标。仅筛选与您相关的指标。
除了 Canton 指标之外,该流程还可以报告(Ledger API 服务器的)Daml 指标。或者,可以使用以下方法包含 JVM 指标:
canton.monitoring.metrics.report-jvm-metrics = yes // 默认否
指标
完整的 Canton 指标清单(包括参与者指标、Sequencer指标、Mediator指标和拼接服务指标)位于 Canton Metrics 中。
日志记录
Canton 使用 Logback 作为日志记录库。所有 Canton 日志均源自记录器 com.digitalasset.canton。默认情况下,Canton 将使用 INFO 日志级别将日志写入文件 log/canton.log,并将 WARN 和 ERROR 记录到 stdout。
可以使用以下选项在命令行上广泛配置 Canton 生成日志文件的方式:* -v(或--verbose)是将 Canton 日志级别设置为 DEBUG 的简短选项。这可能是您将使用的最常见的日志选项。
--debug将除 stdout 之外的所有日志级别设置为DEBUG。标准输出设置为INFO。请注意,外部库的DEBUG日志可能非常嘈杂。--log-level-root=<level>配置根记录器的日志级别。这会更改 Canton 和外部库的日志级别,但不会更改 stdout 的日志级别。--log-level-canton=<level>仅配置Canton logger的日志级别。--log-level-stdout=<level>配置stdout的日志级别。这通常是 Canton 控制台中显示的文本。--log-file-name=log/canton.log配置日志文件的位置。--log-file-appender=flat|rolling|off配置是否以及如何记录到文件。滚动附加程序将根据定义的日期时间模式滚动文件。--log-file-rolling-history=12配置使用滚动追加器时保留的历史文件数量。--log-file-rolling-pattern=YYYY-mm-dd配置文件滚动方式的滚动文件后缀(以及频率)。--log-truncate配置启动时是否应截断日志文件。--log-profile=container为特定设置提供一组默认的日志记录设置。仅支持container配置文件,该配置文件会记录到 STDOUT 和 10 小时有限滚动日志文件历史记录(以避免存储泄漏)。--log-immediate-flush=false关闭日志输出到日志文件的立即刷新。
请注意,如果您使用--log-profile,则命令行参数的顺序很重要。选择配置文件后,可以通过进行调整来覆盖命令行上的配置文件设置。
Canton 支持正常的 log4j 日志记录级别:TRACE、DEBUG、INFO、WARN 和 ERROR。
为了进一步定制,可以使用 JAVA_OPTS 提供自定义 logback configuration。
JAVA_OPTS="-Dlogback.configurationFile=./path-to-file.xml" ./bin/canton --config ...如果您使用自定义日志文件,则用于日志记录的命令行参数将不会产生任何效果,但仍然可以使用 --log-level-canton 和 --log-level-root 来调整根记录器的日志级别。
查看日志
建议使用日志文件查看器(例如 lnav)来查看 Canton 日志并解决问题。除其他功能外,lnav 还具有自动语法突出显示、方便地过滤特定日志消息以及在单个视图中查看不同 Canton 组件的日志文件的能力。这使得查看日志和解决问题比使用标准 UNIX 工具(例如 less 或 grep)更加高效。
使用lnav时,以下功能特别有用:
- 在单个view中查看不同Canton组件的日志文件,根据时间戳合并(
lnav <log1> <log2> ...)。 - 过滤 特定日志消息输入 (
:filter-in <regex>) 或输出 (:filter-out <regex>)。当过滤消息时(例如,使用给定的跟踪 ID),可以跨不同组件跟踪事务,特别是在使用前面描述的单视图功能时。 - 搜索 查找特定日志消息 (
/<regex>) 并在它们之间跳转 (n和N)。 - 自动语法突出显示部分日志消息(例如时间戳)和日志消息本身(例如,
WARN日志消息为黄色)。 - 在错误(
e和E)和警告消息(w和W)之间跳转。 - 有选择地激活和停用不同的过滤器和文件(
TAB和 “ 来激活/停用过滤器)。 - 标记线 (
m) 并在标记线之间来回跳跃 (u和U)。 - 在具有相同trace-id 的行之间来回跳转(
o和O)。
Canton 日志 canton.lnav.json 的自定义 lnav 日志格式 file 捆绑在任何 Canton 版本中。您可以使用lnav -i canton.lnav.json安装它。基于JSON的日志文件(需要使用文件后缀.clog)可以使用canton-json.lnav.json格式文件查看。
详细日志记录
默认情况下,日志记录会忽略详细信息以避免将敏感数据写入日志文件。出于调试或教育目的,您可以使用以下配置开关打开附加日志记录:```none theme={“theme”:{“light”:“github-light”,“dark”:“github-dark”}} canton.monitoring.logging { event-details = true api { message-payloads = true max-method-length = 1000 max-message-lines = 10000 max-string-length = 10000 max-metadata-size = 10000 } }
这将打开`ApiRequestLogger`中的有效负载日志记录,记录每个GRPC API调用,并打开`SequencerClient`和事务树的详细日志记录。请注意,所有附加事件均记录在`DEBUG`级别。
<Note>
请注意,详细的事件日志记录将在 gRPC API 拦截器内进行。当发送或接收的每条消息都被转换为打印精美的字符串时,这会产生顺序瓶颈。如果打开此设置,您将无法获得相同的性能。
</Note>
## 追踪
为了进一步调试,Canton 提供了一个 Trace-id,它允许您跟踪系统中请求的处理情况。 Trace-id 通过 *映射诊断上下文* 暴露给 logback,并且可以使用 `%mdc{trace-id}` 包含在 logback 输出模式中。
通过设置 `canton.monitoring.tracing.propagation = enabled` 配置选项来启用跟踪 ID 传播,该选项默认启用。
您可以配置报告跟踪和跨度的服务,以观察分布式跟踪。请参阅“痕迹”进行预览。
支持 Jaeger 和 Zipkin。例如,Jaeger 报告可以配置如下:
```text theme={"theme":{"light":"github-light","dark":"github-dark"}}
monitoring.tracing.tracer.exporter {
type = jaeger
address = ... // default: "localhost"
port = ... // default: 14250
}此配置连接到正在运行的 Jaeger 服务器以报告跟踪信息。
您可以在 Docker 容器中运行 Jaeger,如下所示:
docker run —rm -it —name jaeger
-p 16686:16686
-p 14250:14250
jaegertracing/一体机:1.22.0
如果您不想使用 Docker,可以在 Download Jaeger 处下载适合您的特定操作系统的二进制文件。解压缩文件,然后运行二进制文件jaeger-all-in-one(不需要参数)。默认情况下,Jaeger 将公开端口 16686(用于其 UI,可以在浏览器窗口中看到)和端口 14250(Canton 将向其报告跟踪信息)。确保正确暴露这些端口。
确保网络中的所有 Canton 节点向同一个 Jaeger 服务器报告,以便准确查看完整的跟踪记录。另外,请确保所有 Canton 节点均可访问 Jaeger 服务器。
除了 jaeger 之外,Canton 节点还可以配置为以 Zipkin 或 OTLP 格式报告。
采样
您可以更改对跨度进行采样并向配置的导出器报告的频率。默认情况下,它总是会报告(monitoring.tracing.tracer.sampler.type = always-on)。您可以将其配置为从不报告 (monitoring.tracing.tracer.sampler.type = always-off),尽管这不太有用。此外,您还可以配置仅报告跨度的特定部分,如下所示:
monitoring.tracing.tracer.sampler = {
type = trace-id-ratio
ratio = 0.5
}您还可以更改基于父级的采样属性。默认情况下,它是打开的(monitoring.tracing.tracer.sampler.parent-based = true)。打开时,如果对其父跨度进行了采样,则对跨度进行采样(根跨度将遵循配置的采样策略)。永远不会有不完整的痕迹;要么对完整轨迹进行采样,要么不进行采样。如果更改此属性,所有跨度都将遵循配置的采样策略,并忽略是否对父级进行采样。
已知限制
并非每个可在日志中观察到的创建的跟踪都会报告给配置的跟踪收集器服务。源自控制台命令或属于事务协议一部分的跟踪大部分都会被报告,而其他类型的跟踪则根据需要添加到报告的跟踪集中。
这与单个 Daml 事务同时导致多个操作的情况不同,例如归档和创建多个合约。在这种情况下,单个跟踪包含整个流程,因为它作为单个事务的一部分发生,而不是外部流程对 Daml 事件做出反应的结果。
痕迹
跟踪包含每个由跨度表示的操作。跟踪是跨度的有向无环图 (DAG),其中跨度之间的边被定义为父/子关系(定义来自 Opentelemetry 术语表)。
坎顿报告了几种类型的痕迹。一个示例:与 Admin API 交互的每个 Canton 控制台命令都会启动一条跟踪,其初始跨度持续整个命令持续时间,包括对特定 Admin API 端点的 GRPC 调用。
<图> <img src=“https://mintcdn.com/cantonfoundation/zmlOjLpKuDjnaObr/images/docs_website/ping-trace.jpg?fit=max&auto=format&n=zmlOjLpKuDjnaObr&q=85&s=26e447ba05de0c40f3b2ddc5830d84ca”样式={{宽度: “100.0%”}} alt=”./images/ping-trace.jpg” width=“2194” height=“1128” data-path=“images/docs_website/ping-trace.jpg” />
{kind=link}
Daml 命令提交的痕迹很重要。当您使用控制台执行 Canton ping 时,会产生图中所示的跟踪结果。 ping 是一种冒烟测试,它发送 Daml 事务(创建 Ping、练习选择 Pong、练习选择 Archive)来测试连接。它使用预先安装在每个 Canton 参与者身上的特定智能合约。该命令使用管理 API 访问预安装的应用程序,然后该应用程序发出在此智能合约上运行的 Ledger API 命令。在此示例中,跟踪包含 18 个跨度。 ping 由参与方1 启动,参与方2 为目标。跟踪重点关注通过Sequencer的消息交换,而不深入挖掘消息处理程序或进一步处理事务。
在某些情况下,由于异步处理,跨度的开始时间可能晚于其父跨度的结束时间。这种情况通常发生在将新操作放入队列中以供稍后处理时,这会立即释放父跨度并结束它。
初始跨度(跨度 1)涵盖 ping 操作的持续时间。在跨度 2 中,参与者节点中的 GrpcPingService 处理控制台发出的 GRPC 请求。它还持续 ping 操作的持续时间。
Canton ping 由三个 Daml 命令组成:
参与方1的管理方创建Ping合约。参与方2的管理方对合约执行Respond消费选择,从而创建Pong合约。参与方1的管理方对其行使Ack的消费选择。
三个 Daml 命令中的第一个命令(Ping 合约的创建)的提交从示例跟踪中的跨度 3 开始。由于下一节中解释的限制,其他两个 Daml 命令提交未链接到此跟踪。可以单独找到它们。无论如何,只有三个 Daml 命令完成后,跨度 2 才会完成。
在跨度 3 处,参与者节点位于 Ledger API 的客户端。在其他用例中,它可能是与参与者集成的应用程序。该跨度持续整个 GRPC 调用的持续时间,该调用在跨度 4 中由服务器端接收,并由跨度 5 中的CantonSyncService 处理。然后请求被接收并确认,但未完全处理。它稍后会异步处理,这意味着跨度 3 到 5 将在处理请求之前完成。
跟踪中缺少的步骤(占跨度 5 和 6 之间间隙的一部分)是:* 同步器路由,参与者决定使用哪个同步器来提交命令。
- 准备要发送的初始消息集。
Canton 交易协议从跨度 6 开始。在此跨度中,参与方1 向sequencer1 发送请求,以对初始确认请求消息集进行排序,作为交易协议第一阶段的一部分。交易协议有七个阶段。
在跨度 7 处,sequencer1 接收请求并注册它。消息的接收不属于此范围的一部分。这将在稍后异步发生。
在跨度 18,作为阶段 2 的一部分,mediator1 收到一条通知消息。它只需要验证并注册它。由于它不需要响应,因此 span 18 没有子级。
作为阶段 3 的一部分,参与方2 接收一条消息(参见范围 8),参与方1 也接收一条消息(参见范围 9)。两个参与者异步验证消息。 参与方2不需要回应。由于它只是一个观察者,因此跨度 8 没有子节点。然而,参与方1 做出了响应,这在跨度 10 处可见。在那里,它再次调用sequencer1,后者在跨度 11 处接收它。
在跨度 12 处,参与方1 收到一条成功发送响应消息,表明其发送给Mediator的消息已成功排序。这是作为第 4 阶段的一部分发生的,其中确认响应被发送到Mediator。Mediator在跨度 13 处接收该消息,并验证该消息(阶段 5)。
在跨度 14 和 15 中,mediator1(现在处于阶段 6)要求sequencer1 将交易结果消息发送给参与者。
为了结束本轮交易协议,参与方1和参与方2分别在跨度16和17处接收消息。消息被异步验证,并且它们对虚拟共享账本的预测被更新(第 7 阶段)。
如前所述,还有另外两个事务提交与此 ping 跟踪未链接,但属于操作的一部分。第二个从标题为 admin-ping.processTransaction 的跨度开始,该跨度由 参与方2 创建。第三个同名但由参与方1发起。
节点健康状态
每个Canton节点都会暴露丰富的健康状态信息。运行:
<node>.health.status返回一个状态对象,它可以是以下之一:
Failure:如果无法确定节点的状态,包括失败原因的错误消息NotInitialized: 如果节点尚未初始化Success[NodeStatus]:是否可以确定状态,包括详细状态
NodeStatus 根据节点类型而有所不同。参与节点响应一条消息,其中包含:
参与方 id:节点的参与者idUptime:该节点的正常运行时间Ports:参与节点公开Ledger和Admin API的端口。Connected 同步器s:参与者正确连接的同步器列表Unhealthy 同步器s:参与者尝试连接的同步器列表,但连接尚未准备好提交命令Active:如果该实例是主动副本,则为 true(如果是高可用性部署的被动实例,则可能为 false。)
同步器节点或Sequencer节点用包含以下内容的消息进行响应:
同步器 id:同步器的唯一标识Uptime:该节点的正常运行时间Ports:同步器公开公共和管理 API 的端口Connected 参与方s:连接的参与者列表Sequencer:一个布尔标志,指示嵌入式Sequencer写入器是否可操作
从 Canton 2.8.6 开始,Sequencer节点还会返回以下附加字段:
Accepts admin changes:一个布尔标志,指示Sequencer是否接受管理员更改
同步器拓扑管理器或中介节点返回:
Node uid:节点的唯一标识Uptime:该节点的正常运行时间Ports:节点托管其 API 的端口Active:如果该实例是主动副本,则为 true(如果是高可用性部署的被动实例,则可能为 false。)此外,所有节点还返回一个components字段,详细说明每个内部运行时依赖项的健康状态。每个节点的实际组件都不同,可以进一步了解节点的当前状态。示例组件包括存储访问、同步器连接和Sequencer后端连接。
健康检查
gRPC健康检查服务
每个 Canton 节点都可以选择配置为启动公开 gRPC Health Service 的 gRPC 服务器。被动节点(有关主动/被动状态的更多信息,请参阅高可用性)返回 NOT_SERVING。在 Kubernetes 环境 中配置活性和就绪探针时请考虑这一点。
计算状态的精确方式可能会发生变化。
以下是放置在节点配置对象内的监视配置示例:
monitoring.grpc-health-server {
address = "127.0.0.1"
port = 5861
}HTTP 健康检查
或者,canton进程可以公开一个 HTTP 端点,指示该进程是否认为它是健康的。这可以用作正常运行时间检查或 Kubernetes 活跃度 probe。如果启用,/health端点将使用 200 HTTP 状态代码(如果健康)或 500(如果不健康,以及不健康原因的纯文本描述)响应 GET HTTP 请求。
要启用此运行状况端点,请将 monitoring 部分添加到 Canton 配置中。由于此健康检查是针对整个流程的,因此将其直接添加到canton配置中,而不是针对特定节点。
canton {
monitoring.health {
server {
port = 7000
}
check {
type = ping
参与方 = 参与方1
interval = 30s
}
}此健康检查导致 参与方1 每 30 秒对其自身进行一次“ledger ping”。如果 ping 成功,则该过程被认为是健康的。
健康转储
您应该提供尽可能多的信息以获得有效的支持。为此,Canton 实施了一个信息收集设施,为支持人员收集关键的基本系统信息。如果您遇到错误并需要帮助,请确保满足以下条件:
- 以交互模式启动 Canton,使用
-v选项启用调试日志记录:./bin/canton -v -c <myconfig>。这提供了控制台提示。 - 按照之前导致错误的步骤重现错误。写下这些步骤,以便将其提供给支持人员。
- 观察到错误后,在 Canton 控制台中输入
health.dump()生成 ZIP 文件。
这将创建一个存储以下信息的转储文件 (.zip):
- 您正在使用的配置,其中删除了所有敏感数据(无密码)。
- 日志文件的摘录。敏感数据不会记录到日志文件中。
- 坎顿指标的当前快照。
- 每个正在运行的线程的堆栈跟踪。
将收集到的信息以及导致问题的具体步骤列表提供给您的支持联系人。提供完整的信息对于帮助解决问题非常重要。
远程健康转储
当运行配置为访问远程节点的控制台时,health.dump() 命令从远程节点收集运行状况数据并将其打包到生成的 zip 文件中。无需采取特殊措施。运行该命令时,可以针对特定节点获取该节点的健康数据。例如:
remote参与方1.health.dump()
当打包大量数据时,增加dump命令的默认超时时间:
health.dump(timeout = 2.minutes)
{/* COPIED_START source=“docs-website:docs/replicated/canton/3.4/参与方/howtos/observe/metrics.rst” hash=“2d6be380” */}
配置指标指标提供有关正在运行的系统的内部状态的定量信息,这对于 monitoring 其运行状况和性能以及 observability 其操作行为至关重要。
参与者节点可以在 HTTP 端点上报告这些指标。然后应该由单独的监控系统(例如 Prometheus)定期抓取这些数据,该系统可以将其存储为时间序列数据,用于查询、警报、仪表板等。
导出抓取指标
通过使用配置canton.monitoring.metrics.reporters = [{ type = prometheus }]启用 Prometheus 报告器来导出应用程序指标
默认情况下,指标将可在 http://<host>:9464/ 以 OpenMetrics 格式进行抓取。
您还可以使用以下命令导出 JVM 指标
canton.monitoring.metrics.reporters.jvm-metrics.enabled = yes
例如
canton.monitoring.metrics {
jvm-metrics.enabled = yes
reporters = [{
type = prometheus
address = 0.0.0.0
// This will expose the prometheus metrics on port 9000
port = 9000
}]
}有关导出的指标的完整列表,请参阅指标参考。
已弃用的记者
支持其他报告器(jmx、graphite 和 csv),但已弃用。任何此类报告器都应迁移到 Prometheus。
可以使用以下方式启用基于 JMX 的报告(仅用于测试目的):
canton.monitoring.metrics.reporters = [{ type = jmx }]此外,指标可以写入文件:
canton.monitoring.metrics.reporters = [{
type = jmx
}, {
type = csv
directory = "metrics"
interval = 5s // default
filters = [{
contains = "canton"
}]
}]或通过 Graphite(向 Grafana)报告,使用:
canton.monitoring.metrics.reporters = [{
type = graphite
port = 2003
interval = 30s // default
filters = [{
contains = "canton"
}]
}]当使用graphite或csv报告器时,Canton会定期评估与给定过滤器匹配的所有指标。仅筛选与您相关的指标。
本文由 CC Privacy Club 根据 Canton Network 官方文档(CC-BY-4.0)整理翻译,仅供学习;实现细节以官方最新版本为准。